In my long post about AI Skills, I made vague reference to the possibilities that Skills provide when it comes to the conversation about open source. I want to take this opportunity to provide one concrete illustration of how a Skill can radically simplify the process of making a model open source.
The WXYZ Model
In a previous writing I introduced a four-stage Markov model called ‘WXYZ’. I originally built it to illustrate a method I had created for building health state transition models. When DARTH created a better way of doing that, I redeveloped WXYZ using their approach. The model repository has been public since that 2021 redevelopment.
Figure 1 - the WXYZ Model
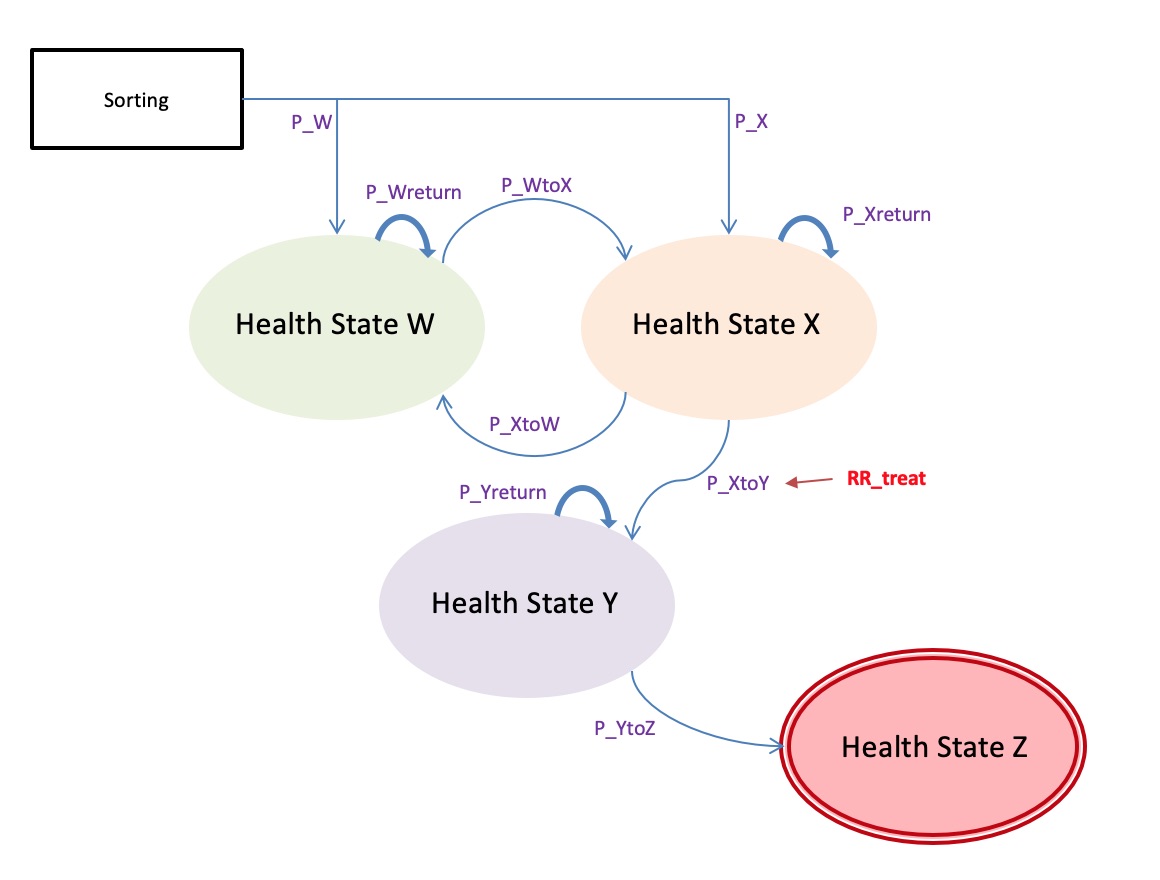
In 2021 I didn’t know how to code a Shiny interface, so I put the parameters in a separate Excel file to make it easier for users to change the values without having to dig around inside the code. The model itself is built like the tutorial it is based on though. Anyone wanting to use it needs to download it, install R and RStudio, then run it in chunks. There’s some user friendliness but it still asks the user to put in some annoying effort as an entry fee.
It’s 2026 now. I still don’t know how to code a Shiny interface. But I do know how to build a Claude skill, and Claude knows how to code a Shiny interface.
Open Source Packaging Skill
I asked Claude to help me build a Skill that would take a model and reformat it so that it is ready to deploy on Github. A successful result would be someone having the ability to call the model directly from RStudio. And because it makes sense, the Skill also instructs Claude to build a Shiny app. The app allows the user to modify all parameter values (including uncertainty). This makes the model fully reusable even to those who don’t code.
The Skill guides Claude through 6 phases of development that culminates in a quality check by the user to ensure that everything was transposed properly. The Skill was explicitly designed to be agnostic to the underlying structure of the model directory, so it had no problem with the parameters being in one file, the functions being in another, and the model itself being in a third.
Running the Skill could not have been easier. I had it loaded into my Claude account already, so I dragged/dropped a .zip of the WXYZ directory into the chat window and asked Claude to convert it into a package:

It did a little beep beep boop, it asked me to confirm some details, and then it got to work. Before it started building it checked in with me about some changes it needed to make in order to match the underlying template. I agreed to them, but if I had said ‘no’ then the AI would have kept things the same.


With the parameter extraction ruled acceptable, Claude got to work building all the other files I needed. It then programmed a Shiny app to run the model based on a template that was provided within the Skill. It was then my turn to run quality checks, which I did. Finally, Claude built me a lockfile to ensure package dependencies remained intact, and it was ready for me to upload to Github.
The huncwxyz Package
The model is now available as a repository on Github.
# Install from GitHub
devtools::install_github("HealthyUncertainty/huncwxyz")
### QUICK START
library(huncwxyz)
# Launch interactive Shiny app
launch_app()
# Or run programmatically
# Deterministic
res <- run_model(n_sim = 1)
res$results_summary
# PSA with 1000 iterations
res_psa <- run_model(n_sim = 1000, seed = 42)
head(res_psa$psa_results)
If you don’t want to go to all the trouble of opening up RStudio, I’ve published the Shiny on the web as well.

Discussion
I can’t be the only person out there who has useful health economic work sitting in a repository or folder they’ve long since abandoned because turning it into a formal package was more work than it was worth. I imagine I’m not the only person who didn’t bother making a Shiny for a model because it was too hard. I am quite confident I’m not the only person who found the prospect of working their way through a long list of software development competencies about as appealing as root canal surgery.
Getting all that done with the Skill wasn’t anything like pulling teeth. I had four plain-language exchanges with a chatbot, and out popped the formatted work. Writing this post describing it was the longest part of the process. Turning the code into a package took maybe 15 minutes cumulatively.
Building the Skill itself took a bit longer. There was a process of trial and error to build all the templates and tighten up the process so it could accept different repository structures. Still even in this more laborious process, it was Claude who did most of the work. I just made suggestions and occasionally pointed out errors. But now that the Skill is built, anyone using it would get the 15-minute experience.
I am holding off on publishing this Skill for the time being. For reasons I go into in my previous post, I think it might be irresponsible to start throwing random AI stuff into the mix before the community has had time to think through and discuss the ramifications. But as I also said in that post, the technology exists and publishing it is no different than publishing a package. I think people usually get these kinds of things peer reviewed first, so that’s the phase of development I’m currently in.
Until then, this can serve as an illustration of the kinds of things Skills could be used for in the open source transition. There are doubtlessly numerous gaps like this - drudgery and inexperience that holds back productive work - that Skills can help to close.
Written with StackEdit.